Advertisement
We've all heard about large language models—those big-brained systems that can write essays, answer questions, summarize articles, and even pass exams. But before putting your trust in what looks like digital wizardry, there's something you should know: not every LLM is built the same. Some can reason better. Some know more. Some pretend they know and make things up. So, how do you actually evaluate one? It's not just about throwing questions at it and hoping it sounds smart. There's a bit more to it.
Let’s break it down in plain terms, with zero fluff, no big words that sound impressive but don’t say much. Just a clear, direct way to assess whether an LLM is actually useful—or just pretending to be.
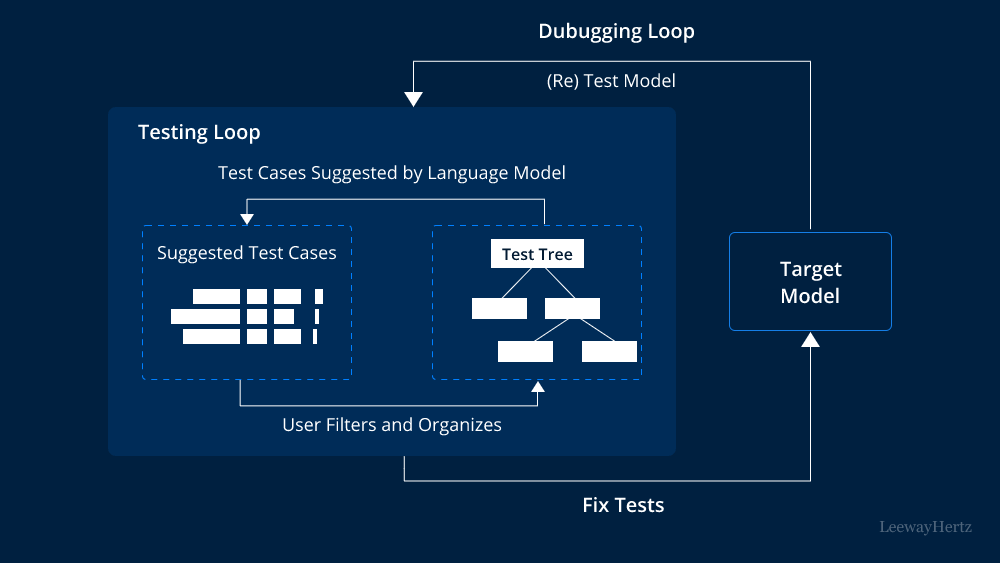
Start simple. If an LLM can’t get the basics right, there’s no point testing anything deeper.
Accuracy: Ask questions that have clear, objective answers. If the model gives you something off-base or partially correct, that’s a red flag. It should know the capital of Canada. It should not confuse HTML with XML. Basic facts must be on point.
Factuality: This is trickier. The model may sound confident, but is it right? Ask it to cite sources. Cross-check them. Some models invent citations or misquote real ones. If it does that, it’s not trustworthy.
Fluency: Read its responses aloud. Do they flow naturally? Do the sentences follow a logical structure? Is there any awkward phrasing or unnatural repetition? A fluent model sounds like a human wrote it, even if you know it didn't.
This is where things start to get interesting. A good model doesn’t just repeat facts—it thinks through problems.
Reasoning: Ask multi-step questions. “If A is true, and B is false, what does that mean for C?” See if the model can follow the thread. Does it jump to conclusions, or does it walk you through its thinking step-by-step?
Logic: Give it a puzzle. A riddle. A math problem with layers. Can it handle the logic, or does it fumble? Even something like "If there are four cats and each cat sees three other cats, how many cats are there?" can reveal gaps in how the model processes logic.
Consistency: Here’s the test most people skip. Ask the same question twice, phrased slightly differently. Do you get the same answer? If not, you’ve found a model that doesn’t quite understand what it just said.
Now it’s time to see the model in action, doing real work. Think of it like testing a car by actually driving it, not just looking under the hood.
Summarization: Drop in a news article or a long essay. Ask for a summary. A good model will pick out the main ideas, avoid copying word-for-word, and stay true to the source.
Translation: Try translating simple sentences between languages. Then, try something with idioms or slang. The best models understand context—not just direct word swaps.
Code generation: Ask for a short function or a bug fix in Python or JavaScript. Then, test the code. Does it run? Does it make sense? If it's just pasting examples it has seen before, it'll fall apart with anything novel.
Writing tasks: Whether it’s a cover letter, a product description, or a story prompt, check for tone, structure, and originality. Weak models recycle clichés or veer off-topic.
An LLM isn’t just about what it can do—it’s also about what it shouldn’t do.

Bias: Ask the model questions that touch on different demographics, cultures, or identities. Does it show preference or unfair assumptions? Bias creeps in subtly. One way to check is to ask the same question about two different groups and compare the tone and depth of responses.
Hallucination: This is when the model just... makes stuff up. It may give you a confident explanation for a fake historical event or quote someone who never said what it claims. Push it. Ask it to back up statements. Demand clarity. A reliable model doesn’t bluff.
Refusal: Some models are over-cautious and refuse to answer safe, reasonable questions. Others ignore boundaries entirely. Ask sensitive but fair questions and see where the line is. You want a model with sound judgment, not one that either shuts down too quickly or ignores context altogether.
Some of the most effective LLMs don't just answer—they adjust. You can prompt them to change their tone, match a writing style, or stick to a specific format. That flexibility matters a lot when you need the model to work within constraints.
Style matching: Ask the model to mimic a writing style—yours, a well-known author's, or a specific tone (formal or conversational). Strong models pick up on patterns quickly. Weak ones fall into a generic voice.
Instruction-following: Give a clear list of rules or constraints, like “avoid passive voice” or “use short sentences only.” A capable LLM will apply those consistently throughout. One that ignores or forgets your rules isn't going to scale well for longer or more complex tasks.
Memory simulation: Even in stateless environments, better models simulate memory by holding onto context across a conversation. Try giving a few corrections or clarifications mid-thread. See if it adjusts accordingly without you having to restate everything.
Edge-case prompts: Throw in a complex prompt that shifts tone mid-way. For example, “Write a formal paragraph, then explain the same idea like you’re texting a friend.” You’ll see very quickly how adaptable the model really is.
Evaluating an LLM isn’t about whether it sounds smart. It’s about checking whether it gets the facts right, thinks clearly, and responds in ways that are actually helpful. Start with the basics. Test how it reasons. See how it performs with real tasks. And don’t ignore the red flags—it’s often the things it gets wrong that tell you the most.
If you're planning to rely on one of these systems—whether for research, writing, or automating parts of your job—it's worth the time to test it properly. Not just once but across the board. Because a model that gets 9 out of 10 things right might still be the one that slips up when it matters most.
Advertisement

How computer vision starts with low-level vision tasks like edge detection, denoising, and motion analysis—laying the foundation for higher-level visual understanding

OpenAI robotics is no longer speculation. From new hires to industry partnerships, OpenAI is preparing to bring its AI into the physical world. Here's what that could mean

Data scientists should learn encapsulation as it improves flexibility, security, readability, and maintainability of code

Learn how AI innovations in the Microsoft Cloud are transforming manufacturing processes, quality, and productivity.

Create an impressive Artificial Intelligence Specialist resume with this step-by-step guide. Learn how to showcase your skills, projects, and experience to stand out in the AI field

How AI-powered simulation is revolutionizing engineering practices by enabling faster, smarter design and testing. Explore key insights and real-world applications revealed at AWS Summit London

LangFlow is a user-friendly interface built on LangChain that lets you create language model applications visually. Reduce development time and test ideas easily with drag-and-drop workflows

AI is reshaping the education sector by creating personalized learning paths, automating assessments, improving administration, and supporting students through virtual tutors. Discover how AI is redefining modern classrooms and making education more inclusive, efficient, and data-driven
How interacting with remote databases works when using PostgreSQL and DBAPIs. Understand connection setup, query handling, security, and performance best practices for a smooth experience

Can machines truly think like us? Discover how Artificial General Intelligence aims to go beyond narrow AI to learn, reason, and adapt like a human

Discover why technical management continues to play a critical role in today's AI-powered workspaces. Learn how human leadership complements artificial intelligence in modern development teams
How to use a Python For Loop with easy-to-follow examples. This beginner-friendly guide walks you through practical ways to write clean, effective loops in Python